Chulalongkorn University Intellectual Repository (CUIR) is a repository that preserves and provides access to information resources that are scholarly works of the University members which include research reports, theses, independent studies, academic projects, textbooks, journal articles, handouts, event videos and other works by the faculties, researchers, students as well as organizations of Chulalongkorn University. The preservation is done by digitization of information resources while the access is made available to both internal and external users. CUIR has adopted Open Archival Information System Model (OAIS Reference Model) as the framework for ingestion, archiving, and dissemination of information resources to comply with the best practice in standard preservation that offer long-term usability.
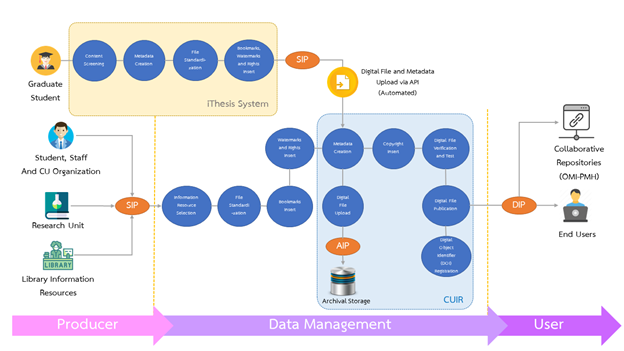
CUIR workflow describes work processes that rely on CUIR Collection Development Policy, Preservation Plan and Creative Common Attribution-NonCommercial-NoDerivatives 4.0 (CC BY-NC-ND 4.0) for digital resource usage.
CUIR workflow consists of the following components:
1. The Producer
2. Data Management
3. The User
1. The Producer
1.1 The creator of the work or CU organization which is the publisher.
The producers in this group are student, lecturer, staff and CU organization that yielded the academic works. These works cover senior project, thesis and independent study being processed without iThesis, journal article, research report, textbook, handout, and other works that were given to the Office of Academic Resources (OAR) by the creator or the publisher with the permission for preservation and online publication using Permission to Publish the Works on Website Form or by sending email to cuir.car.chula.ac.th.
After receiving the academic works, whether in printed or digital format, CUIR staff will check their condition. If they are incomplete, defective or unusable, the staff will notify the owner and request for the new copies.
The digital files that were obtained from the creators will be used as submission information package (SIP) for further handling of the files in the process of data management.
1.2 Student thesis processed by iThesis system
iThesis has been developed by Chulalongkorn University for graduate and PhD students in preparation for their theses from proposal to draft, complete and published copy. If the theses were not categorized as classified or the time frame of restriction had already expired, provided that the author’s consent form which grants the permission to publish both the hard copy and electronic files had already been sent to the Graduate School, the system will use thesis information to create Dublin Core metadata, convert thesis MS-Word files into PDF format, insert bookmarks and CU watermarks as well as set access rights. Digital files will be uploaded as submission information package (SIP) into the database via API that enables transactions between the two systems. The SIP then goes to the process of data management in automated metadata creation and digital file upload as archival information package (AIP).
2. Data Management
The SIP derived from the first procedure will be further processed in 10 steps according to “CUIR Digital File Management and Submission Manual (WI-LIM-05).”
2.1 Information Resource Selection
Contents of academic works that had already been granted permission to publish will be check for their compliance with criteria in CUIR collection development policy. There are also requirements that the works contain no violations to ethical principles, national stability, the Personal Data Protection Act B.E. 2562 and Copyright Act. In case any violations were found later, the works will be withdrawn from the database.
2.2 File Management
This process is to create the archival information package (AIP) from the submission information package (SIP) with the integrity of both digital files and metadata. There are 2 conditions in the process as follows:
2.2.1 If the works from the author are in printed format or different file formats from CUIR requirements, CUIR staff will carry out document scanning or file conversion into standard format according to “CUIR Standard File Formats for the Storage and Services.” This is to prepare the usable files that can be stored and retrieved for long-term use and to avoid the problem of digital file obsolescence.
2.2.2 If the works from the author are digital files already in the required format, CUIR staff will check the files to ensure they are correct, complete and usable as well as change file names into English.
2.3 Bookmark Creation
Bookmarks will be inserted into the files to provide fast and convenient access to the information for the users.
2.4 Watermark and Rights Insert
Chulalongkorn University emblem will be inserted as watermark to indicate rights owner. Access rights setting is also required to prevent file modifications, and misuses.
2.5 Metadata Creation
CUIR uses Dublin Core metadata standard for academic resource description. All titles and all types of the works will have their digital file metadata that cover the elements in three categories.
2.5.1 Content elements include coverage, description, type, relation, source, subject and title.
2.5.2 Intellectual property elements include contributor, creator, publisher and rights.
2.5.3 Instantiation elements include date, format, identifier and language.
Dublin Core metadata is the widely used international standard that are adequate for information searching and flexible enough to add more elements to describe specific characteristics of the work. Dublin Core metadata development is based on the XML which supports data transfer between digital repositories via API or OMI-PMH. The immediate service of CU theses and independent studies are then made possible by the automated transfer of metadata and digital files from Graduate School iThesis system into CUIR. Harvesting of CUIR metadata for their own databases are also feasible for collaborative repositories as well.
For subjects of the resources which are controlled vocabulary, Online Thai Subject Headings by the Cataloging Librarian Working Group of the Thai Academic Library and the Library of Congress Subject Headings (LCSH) are used.
2.6 Digital File Upload
After metadata creation is finished, the staff will upload the archival information package (AIP) into the archival storage of DSpace software in the process of digital file preservation for long-term access to the resources.
2.7 Copyright Insert
Copyright information will be attached after metadata creation and digital files upload are completed.
2.8 Digital File Verification and Test
In this procedure CUIR staff will do the last check for the quality of metadata and digital files. The metadata must be correct and complete with sufficient details for user search and decision while the files available are obliged to follow the terms and conditions of the predetermined access rights.
2.9 Digital File Publication
CUIR staff will confirm the publication of the dissemination information package (DIP) derived after digital file verification and test. The resource is now ready for the users to find and download.
2.10 Digital Object Identifier (DOI) Registration
In order to secure long-term access to CU academic works and backup storage for resource preservation, CUIR staff will register the resource with Digital Research Information Centre, National Research Council of Thailand for digital object identifier (DOI). DOI staff will verify the metadata before uploading the files to their system and assign a DOI for the resource. The DOI will be returned and attached to resource metadata in CUIR automatically via the API.
3. The User
3.1 Public Users
CUIR is an open access repository that allows CU communities and general public to search, access and download digital files of CU academic works from online database anytime.
3.2 Collaborative Repositories
Collaborative repositories are able to collect CUIR metadata using the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) which enhances the accessibility of CUIR resources. Download links in those repositories still need to be redirected to CUIR website anyway.
คลังปัญญาจุฬาฯ เพื่อประเทศไทย (Chulalongkorn University Intellectual Repository : CUIR) เป็นคลังจัดเก็บและให้บริการสารสนเทศที่เป็นภูมิปัญญาของจุฬาลงกรณ์มหาวิทยาลัย ได้แก่ รายงานการวิจัย วิทยานิพนธ์ สารนิพนธ์ โครงงานทางวิชาการ หนังสือตำรา บทความทางวิชาการ เอกสารประกอบการบรรยาย วีดีทัศน์บันทึกเหตุการณ์ และผลงานอื่นๆ ทั้งของคณาจารย์ นักวิจัย นิสิต และหน่วยงานต่างๆ ของจุฬาลงกรณ์มหาวิทยาลัย โดยวิธีการสงวนรักษา (Preservation) การแปลงสภาพทรัพยากรสารสนเทศให้เป็นสื่อดิจิทัล (Digitize) และการเข้าถึง (Access) บริการของผู้ใช้บริการทั้งภายในและภายนอกมหาวิทยาลัย ทางหน่วยงานได้นำแนวกรอบความคิดระบบสารสนเทศจดหมายเหตุแบบเปิด (Open Archival Information System) หรือ OAIS Reference Model มาใช้เป็นมาตรฐานอ้างอิงการดำเนินงานของคลังปัญญาจุฬาฯ เพื่อให้กระบวนการทำงานเป็นไปตามแนวทางการปฏิบัติที่ดี มีวิธีการสงวนรักษาที่เป็นมาตรฐานและเป็นที่ยอมรับ สามารถเข้าถึงข้อมูลได้ในระยะยาว และสามารถนำข้อมูลกลับมาใช้ใหม่ได้ตลอดเวลา
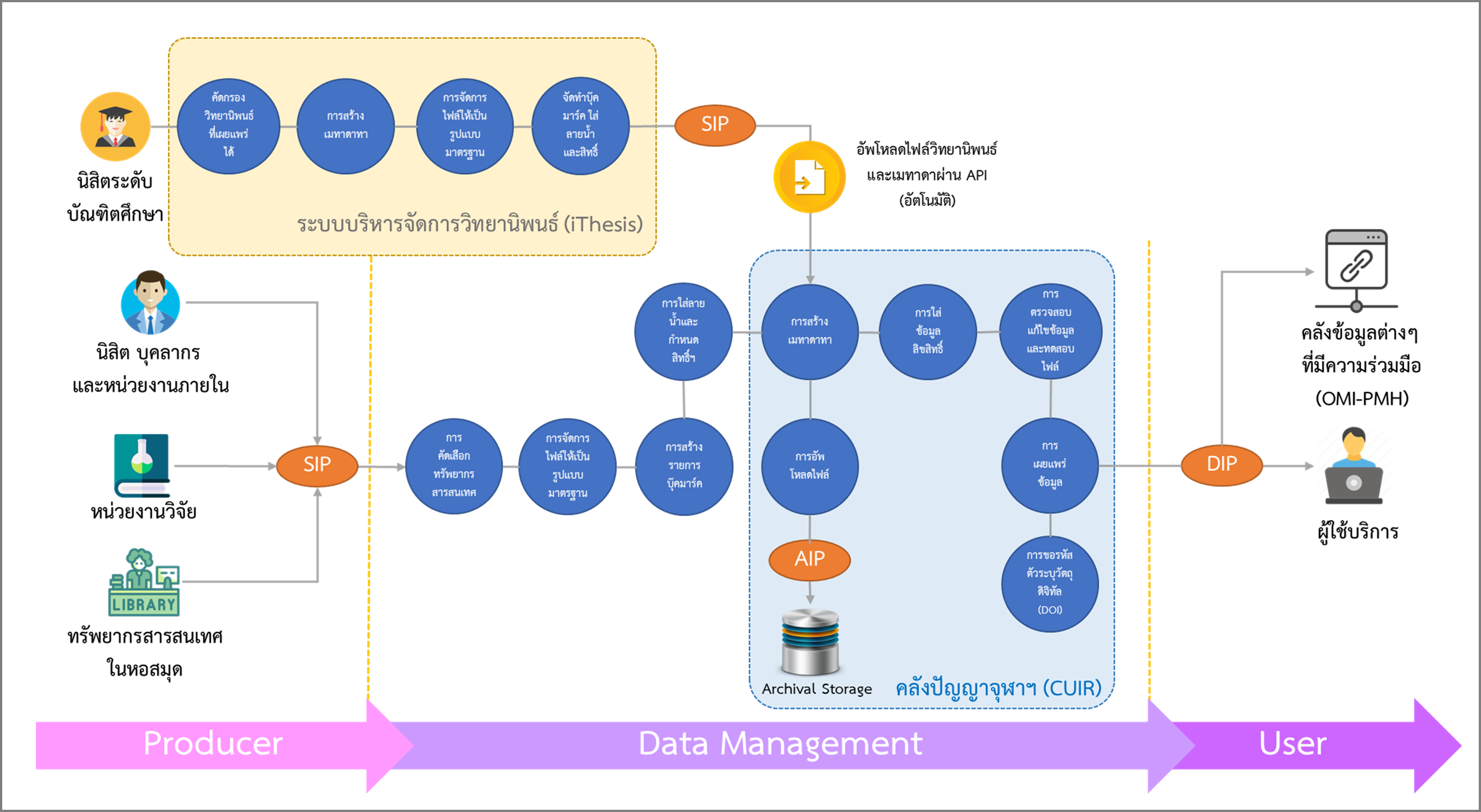
ผังกระแสงานของคลังปัญญาจุฬาฯ นี้ได้นำมาใช้เป็นขั้นตอนปฏิบัติงาน และได้ยึดตามนโยบายคลังปัญญาจุฬาฯ เพื่อประเทศไทย, เอกสารการสงวนรักษาทรัพยากรสารสนเทศดิจิทัล คลังปัญญาจุฬาฯ เพื่อประเทศไทย (CUIR) และ สัญญาอนุญาตการใช้งานแบบเปิด Creative Commons (CC BY-NC-ND 4.0) สำหรับการใช้งานทรัพยากรสารสนเทศดิจิทัล
ผังกระแสงานของคลังปัญญาจุฬาฯ แบ่งการทำงานออกเป็น 3 ส่วน ได้แก่
1. ผู้ผลิตสารสนเทศ (Producer)
2. การจัดการข้อมูลสารสนเทศ (Data Management)
3. ผู้ใช้บริการ (User)
1. ผู้ผลิตสารสนเทศ (Producer)
แบ่งออกเป็น 2 กลุ่ม ดังนี้
1.1 ผู้ผลิตสารสนเทศ / หน่วยงานต่างๆ ภายในจุฬาฯ ที่เป็นผู้จัดทำเผยแพร่
ผู้ผลิตสารสนเทศในกลุ่มนี้ได้แก่ นิสิต อาจารย์ นักวิจัย บุคลากร และหน่วยงานต่างๆ ในจุฬาลงกรณ์มหาวิทยาลัยที่ได้จัดทำเอกสารทางวิชาการต่างๆ ได้แก่ โครงงานทางวิชาการ (Senior Project) สารนิพนธ์และวิทยานิพนธ์ (Independent Study and Thesis) ที่จัดทำภายนอกระบบบริหารจัดการวิทยานิพนธ์ บทความทางวิชาการ (Article) รายงานการวิจัย ตำราวิชาการ เอกสารประกอบการสอน และผลงานทางวิชาการอื่นๆ ที่ผู้เป็นเจ้าของ หรือหน่วยงานต่างๆ ภายในจุฬาฯ ได้ส่งมอบตัวเล่ม หรือไฟล์ต่างๆ ให้กับทางสำนักงาน เพื่อให้ทำการสงวนรักษา และมอบสิทธิ์การอนุญาตเผยแพร่ทางออนไลน์ให้กับทางสำนักงานด้วยแบบฟอร์มการอนุญาตเผยแพร่ผลงานวิชาการบนเว็บไซต์ (FM-LIM-13) และ/หรือ ทางอีเมล์ [email protected]
เมื่อได้รับเอกสารผลงานทางวิชาการมาไม่ว่าจะเป็นในรูปของสื่อสิ่งพิมพ์ หรือสื่อดิจิทัล ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะดำเนินการตรวจสอบความถูกต้อง ครบถ้วนสมบูรณ์ของผลงานทั้งหมดก่อน หากสิ่งที่ได้รับมายังไม่ครบถ้วนสมบูรณ์ บางส่วนขาดหายไป ชำรุด หรือเปิดใช้งานไม่ได้จะแจ้งให้ทางผู้ที่เป็นเจ้าของส่งผลงานมาให้ทางคลังปัญญาจุฬาฯ ใหม่อีกครั้งหนึ่ง
ทั้งนี้ไฟล์ดิจิทัลที่ได้รับจากผู้ผลิตสารสนเทศในส่วนนี้จะเป็นชุดไฟล์ต้นฉบับสำหรับการนำเข้าคลังปัญญาจุฬาฯ (Submission Information Package : SIP) ซึ่งจะนำไปดำเนินการจัดการไฟล์ดิจิทัลต่อในขั้นตอนที่ 2 การจัดการข้อมูลสารสนเทศ
1.2 ผลงานของนิสิตที่รับผ่านระบบบริหารจัดการวิทยานิพนธ์ (iThesis)
ระบบบริหารจัดการวิทยานิพนธ์ (iThesis) เป็นระบบที่จุฬาลงกรณ์มหาวิทยาลัยพัฒนาขึ้นมาเพื่อให้นิสิตระดับปริญญาโท ทั้งหลักสูตรแผน ก และ ข. และระดับปริญญาเอกได้ใช้ระบบดังกล่าวในการจัดทำวิทยานิพนธ์ตั้งแต่ขั้นตอนการจัดทำโครงร่าง (Proposal) การจัดทำฉบับร่าง (Draft) ฉบับสมบูรณ์ (Complete) และฉบับเผยแพร่ในคลังปัญญาจุฬาฯ ทั้งนี้เมื่อจัดทำวิทยานิพนธ์เสร็จเรียบร้อยแล้ว และวิทยานิพนธ์ดังกล่าวให้เผยแพร่ได้ตามปกติ ไม่ปกปิด หรือพ้นระยะเวลาการปกปิดแล้ว ตามที่นิสิตเจ้าของวิทยานิพนธ์ได้กำหนดอนุญาตสิทธิ์การเผยแพร่วิทยานิพนธ์ทั้งตัวเล่มและไฟล์อิเล็กทรอนิกส์ใน แบบฟอร์มการส่งวิทยานิพนธ์ (Consent Form) กับทางบัณฑิตวิทยาลัยระบบจะทำการดึงรายการต่างๆ ในวิทยานิพนธ์ฉบับนั้นๆ มาสกัด และสร้างเป็นเมทาเดทาตามมาตรฐานดับบลินคอร์ เมทาดาทา (Dublin Core Metadata) ส่วนไฟล์วิทยานิพนธ์จะทำการแปลงสภาพจากไฟล์ MS-Word ให้เป็นไฟล์ PDF เพื่อให้เหมาะสมต่อการใช้งาน พร้อมทั้งจัดทำบุ๊คมาร์ก (Bookmark) ลงในไฟล์ ใส่ลายน้ำสัญลักษณ์จุฬาลงกรณ์มหาวิทยาลัยเพื่อแสดงความเป็นเจ้าของกรรมสิทธิ์ และกำหนดสิทธิ์การใช้ไฟล์ จากนั้นทางเจ้าหน้าที่ของสำนักงานวิทยทรัพยากรทำการอัพโหลดไฟล์วิทยานิพนธ์ ซึ่งก็คือ “Submission Information Package” หรือ SIP ที่ได้รับอนุญาตให้เผยแพร่เข้าสู่คลังปัญญาจุฬาฯ โดยอัตโนมัติ ผ่านทาง API ที่เชื่อมระหว่างระบบทั้ง 2 ซึ่งจะเป็นการเข้าสู่ส่วนการจัดการข้อมูลสารสนเทศ ในช่วงของขั้นตอน 2.5 การสร้าง เมทาดาทา แต่จะเป็นสร้างเมทาดาทาโดยอัตโนมัติ พร้อมทั้งอัพโหลดไฟล์ดิจิทัล เข้าไปเป็นชุดไฟล์สำหรับการจัดเก็บ (Archival Information Package : AIP)
2. การจัดการข้อมูลสารสนเทศ (Data Management)
เมื่อคลังปัญญาจุฬาฯ ได้รับเอกสารหรือชุดไฟล์ต้นฉบับสำหรับการนำเข้า (Submission Information Package : SIP) จากทางส่วนที่ 1 ผู้ผลิตสารสนเทศ (Producer) แล้ว ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะนำไฟล์ชุดดังกล่าวมาเข้าสู่กระบวนการจัดการข้อมูลสารสนเทศ (Data Management) ตาม “คู่มือการจัดการไฟล์ดิจิทัลและการนำข้อมูลเข้าสู่คลังปัญญาจุฬาฯ (CUIR)” (WI-LIM-05) โดยแบ่งออกเป็น 10 ขั้นตอน ดังนี้
2.1 การคัดเลือกทรัพยากรสารสนเทศดิจิทัล (Selections)
ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะดำเนินการคัดเลือกผลงานทางวิชาการที่ได้รับอนุญาตให้เผยแพร่ว่ามีคุณสมบัติตรงตามหลักเกณฑ์นโยบายคลังปัญญาจุฬาฯ เพื่อประเทศไทยหรือไม่ และผลงานดังกล่าวต้องไม่ขัดหรือละเมิดต่อหลักจริยธรรม ความมั่นคงของประเทศ พ.ร.บ.ข้อมูลส่วนบุคคล พ.ศ. 2562 และ พ.ร.บ. ลิขสิทธิ์ที่เกี่ยวข้อง ทั้งนี้หากตรวจสอบพบในภายหลังจะดำเนินการถอดถอนผลงานออกจากการให้บริการในคลังปัญญาจุฬาฯ ทันที
2.2 การจัดการไฟล์ให้เป็นรูปแบบมาตรฐาน (File Management)
เป็นการดำเนินการเพื่อเปลี่ยนชุดไฟล์ต้นฉบับสำหรับการนำเข้า (Submission Information Package : SIP) ให้เป็นชุดไฟล์สำหรับการจัดเก็บ (Archival Information Package : AIP) โดยต้องจัดทำให้เป็นไปอย่างครบถ้วนสมบูรณ์ (Integrity) ทั้งในส่วนของไฟล์ดิจิทัล และเมทาดาทา การดำเนินการในขั้นตอนนี้ แบ่งออกเป็น 2 กรณี ดังนี้
2.2.1 กรณีทางคลังปัญญาจุฬาฯ ได้รับผลงานทางวิชาการมาในรูปแบบสื่อสิ่งพิมพ์หรือไฟล์สื่อดิจิทัลอื่นๆ แต่ไม่ตรงตามรูปแบบที่ทางคลังปัญญาจุฬาฯ ต้องการ ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะดำเนินการสแกนเอกสารเป็นไฟล์ดิจิทัล และ/หรือแปลงไฟล์ดิจิทัลอื่นๆ ให้เป็นไฟล์ดิจิทัล (Digitize) ตามรูปแบบมาตรฐาน (File Format) สากล ตามเอกสาร “มาตรฐานรูปแบบไฟล์ในการจัดเก็บและให้บริการในคลังปัญญาจุฬาฯ” เพื่อให้ไฟล์ดิจิทัลต่างๆ ที่อยู่ในคลังปัญญาจุฬาฯ มีรูปแบบที่เหมาะสมต่อการใช้งาน สามารถจัดเก็บและนำกลับมาใช้ใหม่ได้ในระยะยาวอย่างยั่งยืน และช่วยลดปัญหาไฟล์ดิจิทัลล้าสมัย
2.2.2 กรณีทางคลังปัญญาจุฬาฯ ได้รับผลงานทางวิชาการมาในรูปแบบไฟล์สื่อดิจิทัลตามที่คลังปัญญาจุฬาฯ กำหนดแล้ว ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะทำการตรวจสอบความถูกต้อง ความครบถ้วนสมบูรณ์ และต้องเปิดใช้งานได้ รวมทั้งเปลี่ยนชื่อไฟล์ให้เป็นภาษาอังกฤษด้วย
2.3 การสร้างรายการบุ๊คมาร์ค (Create bookmark)
ผลงานวิชาการที่เป็นไฟล์เอกสารดิจิทัล ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะดำเนินการสร้างรายการบุ๊คมาร์คลงในไฟล์เพื่อให้ผู้ใช้งานสะดวกในค้นหาหรือเข้าถึงเนื้อหาที่ต้องการในไฟล์ได้อย่างสะดวกและรวดเร็วมากยิ่งขึ้น
2.4 การใส่ลายน้ำและการกำหนดสิทธิ์การใช้งาน (Add watermark and set permission)
เจ้าหน้าที่คลังปัญญาจุฬาฯ ดำเนินการใส่ลายน้ำ (Watermark) ตราสัญลักษณ์จุฬาลงกรณ์มหาวิทยาลัยลงในไฟล์เอกสารดิจิทัลเพื่อแสดงความเป็นเจ้าของกรรมสิทธิ์ และกำหนดสิทธิ์การใช้งานไฟล์เอกสารดิจิทัล เพื่อป้องกันการแก้ไขไฟล์ การใช้ไฟล์ที่เป็นลักษณะของการละเมิด หรือการนำไฟล์ไปใช้ผิดวัตถุประสงค์ หรือเพื่อประโยชน์ทางการค้า
2.5 คลังปัญญาจุฬาฯ ใช้มาตรฐานการลงรายการข้อมูลเมทาดาทาด้วย ดับบลิน คอร์ เมทาดาทา (Dublin Core Metadata) มาใช้เป็นรูปแบบการลงรายการของผลงานวิชาการ ทั้งนี้เจ้าหน้าที่จะดำเนินการสร้างรายการเมทาดาทาให้กับผลงานวิชาการในคลังปัญญาจุฬาฯ ทุกชื่อเรื่อง และทุกประเภทเพื่อพรรณารายการเกี่ยวกับข้อมูลต่างๆ ในไฟล์ดิจิทัล และต้องครอบคลุมหน่วยข้อมูลย่อย ทั้ง 3 กลุ่ม ได้แก่
2.5.1 หน่วยข้อมูลย่อยที่เกี่ยวกับเนื้อหาของทรัพยากรสารสนเทศ ได้แก่ ชื่อเรื่อง หัวเรื่อง ภาษา ขอบเขต แหล่งที่มา และความสัมพันธ์กับงานต่างๆ
2.5.2 หน่วยข้อมูลย่อยที่เกี่ยวกับทรัพย์สินทางปัญญา ได้แก่ ชื่อผู้แต่ง ผู้ร่วมสร้างสรรค์ผลงาน สำนักพิมพ์ และสิทธิ์
2.5.3 หน่วยข้อมูลย่อยที่เกี่ยวกับรูปแบบที่ปรากฎ ได้แก่ วันเดือนปีที่ผลิต ประเภท รูปแบบที่ใช้นำเสนอ และตัวระบุเอกลักษณ์หรือรหัสต่างๆ
การลงรายการด้วยดับบลิน คอร์ เมทาดาทา นิยมใช้กันอย่างแพร่หลายและเป็นที่ยอมรับในระดับสากล มีความยืดหยุ่น เพียงพอต่อการสืบค้นของผู้ใช้บริการ และสามารถเพิ่มเติม element ที่ต้องการอธิบายคุณลักษณะเฉพาะของผลงานนั้นๆ ได้อีกด้วย ทำให้ผู้ใช้บริการสามารถสืบค้นข้อมูลได้ง่าย และเข้าถึงไฟล์เอกสารได้อย่างรวดเร็วขึ้น และดับบลิน คอร์ เมทาดาทายังพัฒนาอยู่บนพื้นฐานของมาตรฐาน XML จึงรองรับการรับ-ส่งข้อมูลระหว่างคลังสารสนเทศดิจิทัลผ่านทาง API และ/หรือโปรโตคอล OMI-PMH จึงทำให้คลังปัญญาจุฬาสามารถรับข้อมูลเมทาดาทา และไฟล์เอกสารดิจิทัลจากระบบบริหารจัดการวิทยานิพนธ์ (iThesis) ที่บัณฑิตวิทยาลัย จุฬาลงกรณ์มหาวิทยาลัยให้นิสิตใช้ในการจัดทำวิทยานิพนธ์และสารนิพนธ์ได้โดยอัตโนมัติ ทำให้สามารถให้บริการข้อมูลวิทยานิพนธ์ และสารนิพนธ์ ได้อย่างรวดเร็วขึ้น อีกทั้งยังทำให้คลังสารสนเทศอื่นๆ ที่มีความร่วมมือกันสามารถมาเก็บเกี่ยวเมทาดา (Harvesting) ของคลังปัญญาจุฬาฯ เอาไปใส่เข้าฐานข้อมูลของตนเองได้โดยอัตโนมัติเช่นเดียวกัน
สำหรับรายการหัวเรื่องซึ่งเป็นศัพท์ควบคุม ทางคลังปัญญาจุฬาฯ ใช้คู่มือ หัวเรื่องภาษาไทยออนไลน์ (Online Thai Subject Headings) ของคณะทำงานฝ่ายวิเคราะห์ทรัพยากรสารสนเทศ ห้องสมุดสถาบันอุดมศึกษา สำหรับภาษาไทย และใช้คู่มือหัวเรื่อง Library of Congress Subject Heading (LCSH) สำหรับภาษาอังกฤษ
2.6 การอัพโหลดไฟล์ (Upload file)
เมื่อสร้างรายการเมทาดาทาเสร็จเรียบร้อยแล้ว ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะดำเนินการอัพโหลดไฟล์สำหรับการจัดเก็บ (Archival Information Package : AIP) เข้าสู่คลังปัญญาจุฬาฯ โดยจัดเก็บไฟล์ไว้ในส่วน Archival Storage ของโปรแกรม DSpace เพื่อทำการสงวนรักษา และให้เข้าถึงไฟล์ดิจิทัลได้ในระยะยาว
2.7 การใส่ข้อมูลลิขสิทธิ์ (Add license policy)
เมื่อจัดทำรายการเมทาดาทา และอัพโหลดไฟล์เรียบร้อยแล้ว ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะดำเนินการใส่ข้อมูลรายละเอียดเกี่ยวกับลิขสิทธ์ของผลงานนั้นๆ ลงในคลังปัญญาจุฬาฯ
2.8 การตรวจสอบ แก้ไขข้อมูล และทดสอบไฟล์ (Check, edit metadata and test file)
เจ้าหน้าที่คลังปัญญาจุฬาฯ ดำเนินการตรวจสอบข้อมูล แก้ไขข้อมูลเมทาดาทา และตรวจสอบไฟล์เป็นครั้งสุดท้าย เพื่อให้มั่นใจว่าระเบียนผลงานวิชาการนั้นๆ มีรายการเมทาดาทาที่มีความถูกต้อง ครบถ้วนสมบูรณ์ และมีรายละเอียดที่เพียงพอให้ผู้ใช้สามารถสืบค้น อ่าน และพิจารณาในการใช้งานได้ และไฟล์ที่ผู้ใช้ดาวน์โหลดไปเป็นตามเงื่อนไขที่ได้กำหนดสิทธิ์การใช้งานไว้
2.9 การเผยแพร่ข้อมูล (Publish Data)
เมื่อทดสอบไฟล์ และตรวจสอบข้อมูลในขั้นตอนสุดท้ายเสร็จแล้ว ทางเจ้าหน้าที่คลังปัญญาจุฬาฯ จะทำการยืนยันการเผยแพร่ข้อมูลในระบบ DSpace เพื่อให้ผู้ใช้บริการสามารถสืบค้นและดาวน์โหลดชุดไฟล์เผยแพร่ (Dissemination Information Package : DIP) เพื่อนำไปใช้งานได้
2.10 การขอรหัสตัวระบุวัตถุดิจิทัล (Create DOI)
เพื่อให้ผลงานทางวิชาการต่างๆ ที่อยู่ในคลังปัญญาจุฬาฯ สามารถเข้าถึงได้ในระยะยาว อีกทั้งยังเป็นแหล่งสำรองไฟล์ที่จะช่วยให้การสงวนรักษาผลงานวิชาการของคลังปัญญาจุฬาฯ มีประสิทธิภาพ ทางเจ้าหน้าทึ่คลังปัญญาจุฬาฯ จะดำเนินการส่งข้อมูลเมทาดาทาของผลงานวิชาการที่ดำเนินการนำข้อมูลเข้าสู่คลังปัญญาจุฬาฯ เรียบร้อยแล้ว ส่งไปยังระบบการขอรหัสตัวระบุวัตถุดิจิทัล (Digital Object Identifier : DOI) จากทางศูนย์สารสนเทศการวิจัย สำนักงานการวิจัยแห่งชาติ (วช.) ผ่านทาง APIทั้งนี้เมื่อทางเจ้าหน้าที่ DOI ของวช. ได้รับข้อมูลแล้วก็จะดำเนินการตรวจสอบเมทาดาทา ทำการอัพโหลดไฟล์เข้าสู่ระบบจัดเก็บไฟล์ของ วช. และออกรหัสตัวระบุวัตถุดิจิทัล (DOI) จากระบบของ วช. และรหัส DOI ดังกล่าวจะถูกส่งกลับมาและเติมข้อมูลรหัส DOI เข้าสู่คลังปัญญาจุฬาฯ โดยอัตโนมัติ
3. ผู้ใช้บริการ (User)
แบ่งออกเป็น 2 กลุ่ม ได้แก่
3.1 ผู้ใช้บริการ (Users)
คลังปัญญาจุฬาฯ ให้บริการสืบค้นและดาวน์โหลดไฟล์ผลงานทางวิชาการได้ในลักษณะเป็นฐานข้อมูลแบบเปิดเสรี (Free Open Access) ดังนั้นผู้ใช้บริการทั้งภายในและภายนอกจุฬาลงกรณ์มหาวิทยาลัยสามารถสืบค้นผ่านทางเว็บไซต์คลังปัญญาจุฬาฯ ได้ตลอดเวลา
3.2 คลังข้อมูลต่างๆ ที่มีความร่วมมือกับคลังปัญญาจุฬาฯ (Information Repository)
คลังปัญญาจุฬาฯ มีความร่วมมือกับคลังสารสนเทศดิจิทัลภายนอกโดยวิธีการเก็บเกี่ยวเมทาทาดา (Harvesting) จากคลังปัญญาจุฬาฯ ไปใส่ในคลังสารสนเทศภายนอกผ่านทางโปรโตคอล OAI-PMH ทำให้เพิ่มโอกาสในการเข้าถึงทรัพยากรสารสนเทศของคลังปัญญาจุฬาฯ ส่วนไฟล์ดิจิทัลนั้นทางผู้ใช้บริการยังคงต้องคลิกลิงค์ URL ที่อยู่ในคลังสารสนเทศแล้วกลับมาดาวน์โหลดไฟล์ที่หน้าเว็บไซต์คลังปัญญาจุฬาฯ ตามเดิม
